5.4 KiB
Training Environment
This documentation is for advanced users which are aware of following tools: git, python/R, cuda, pytorch/tensorflow and basic container knowledge.

Overview
Available are two worker agents with
- 12 physical CPUs
- 40 GB memory
- 20 GB Nvidia GPU memory
- 100 GB Hdd Diskspace
Only two pipelines can run in parallel to ensure having the promised hardware resources. If more jobs occur, they will be stored in a queue and released after the fifo principle. Storage is not persistent - every build/training job needs to saved somewhere external.
Development
Git
Create a new git repository and commit your latest code here: https://git.sandbox.iuk.hdm-stuttgart.de/
Repositories can be private or public - depends on your use case.
CI
Connect your newly created repository here: https://ci.sandbox.iuk.hdm-stuttgart.de/
-
After login, click on "+ Add repository"

-
Enable the specific repository
-
Go to the repositories overview site and select your enabled repository
-
Go to settings (clicking the settings icon)
-
Set a reasonable timeout in minutes (e.g. 360 minutes for 6hours) if some training crashes/hangs
-
Add additional settings like secrets or container registries, see the official documentation for additional settings
Pipeline File
An example script can be found here:
https://git.sandbox.iuk.hdm-stuttgart.de/grosse/test-ci
- Create a new file in your repository
.woodpecker.yml(or different regarding repository settings above) - The content can look like following:
steps:
"train":
image: nvcr.io/nvidia/tensorflow:23.10-tf2-py3
commands:
- echo "starting python script"
- python run.py
"compress and upload":
image: alpine:3
commands:
- apk --no-cache add zip curl
- zip mymodel.zip mymodel.keras
- curl -F fileUpload=@mymodel.zip https://share.storage.sandbox.iuk.hdm-stuttgart.de/upload
See the official documentation for the syntax.
Generally, the pipeline is based on different steps, and in each step, another container environment can be chosen. In the example above, first an official tensorflow container with python 3 is used to run the training python script. In most cases you can find predefined containers at Dockerhub or GPU supported containers at NVIDIA. If needed, custom images can be created and stored internally (on the Sandbox Git package repository) or any other public available container repository. In the second step, the model gets compressed and pushed on the temp. sandbox storage.
- Commit and push
- See current state of the pipelines at the overview site
Exporting trained model
We provide a 3-months disposal internal storage.
You can either use the a simple curl command curl -F fileUpload=@mymodel.zip https://share.storage.sandbox.iuk.hdm-stuttgart.de/upload to upload a file or a simple python script
import requests
import os
myurl = 'https://share.storage.sandbox.iuk.hdm-stuttgart.de/upload'
print("uploading file")
files = {
'fileUpload':('mymodel.keras', open('mymodel.keras', 'rb'),'application/octet-stream')
}
response = requests.post(myurl, files=files)
print(response,response.text)
which returns a json with the download url of your uploaded file.
{"PublicUrl":"https://storage.sandbox.iuk.hdm-stuttgart.de/upload/49676006-94e4-4da6-be3f-466u786768979/mymodel.keras","Size":97865925,"Expiration":"2024-03-30T00:00:00Z"}
Troubleshooting:
- The first time an external container is pulled, depending on the size, container images can take quite a while as different organization (like dockerhub) limit the download speed. The Sandbox git also supports hosting container images...
- Choose a proper way to output some reasonable logs during your training, so it wont spam the logs too heavily
- training exists after 60 minutes: increase maximum duration in the ci repository settings
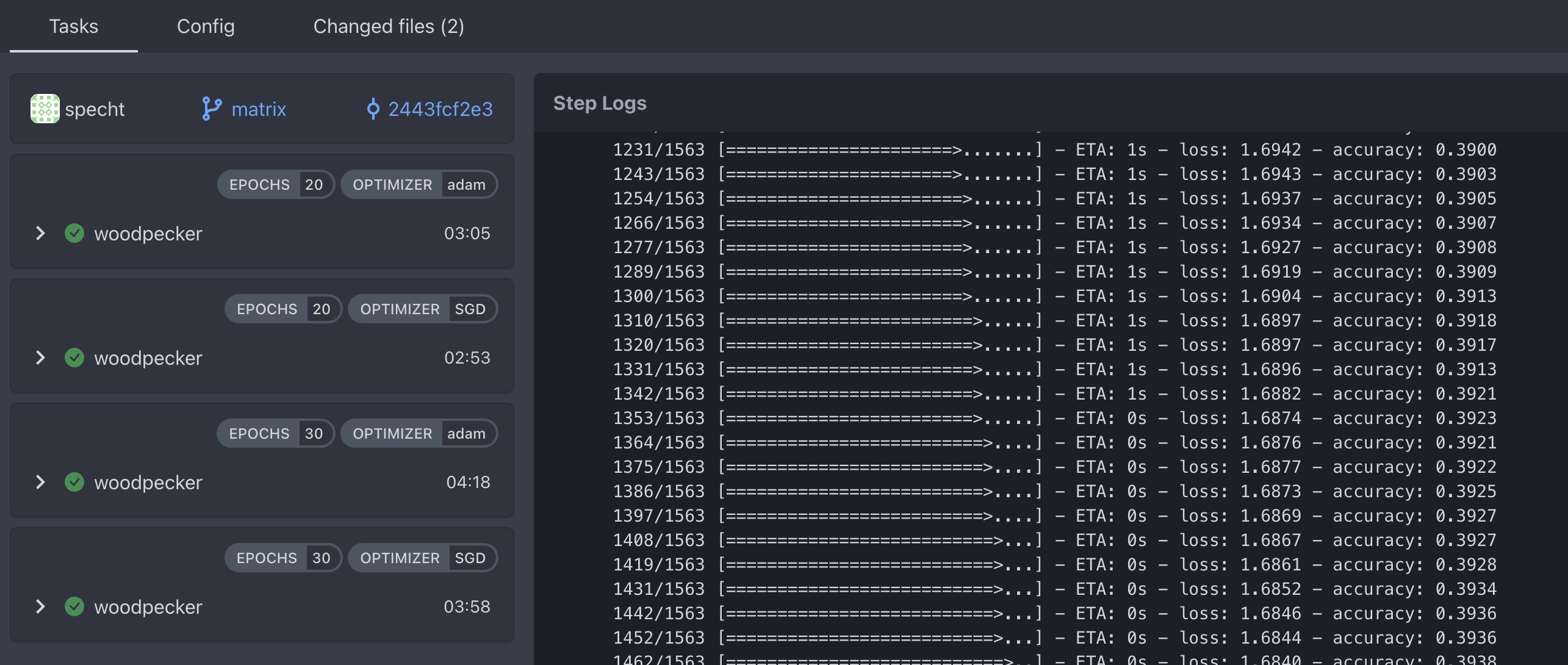
Advanced Parameters (Matrix Workflos)
The woodpecker cli yaml defintion files support matrix workflows, such that multiple pipeline runs are executed with all combinations of the predefined variables.
See the test-ci matrix branch as an example to define multiple pipeline runs with different epochs and optimizers. In the CI it is showed with different label for each parameter: